2023毕业快乐
年纪越大,感到时光流逝的就越快。转眼间,就已经到了2023年。比我大一届的师兄师姐们就要毕业了。这篇博客主要放照片用,没有什么太多的文字内容。
祝各位毕业的师兄师姐前程似锦,生活精彩。🎉🎉🎉

年纪越大,感到时光流逝的就越快。转眼间,就已经到了2023年。比我大一届的师兄师姐们就要毕业了。这篇博客主要放照片用,没有什么太多的文字内容。
祝各位毕业的师兄师姐前程似锦,生活精彩。🎉🎉🎉
最近,清华大学和商汤发表了一篇名为《Ghost in the Minecraft: Generally Capable Agents for Open-World Environments via Large Language Models with Text-based Knowledge and Memory》的文章,简称GITM。很有意思,感兴趣的朋友可以读一下原文。
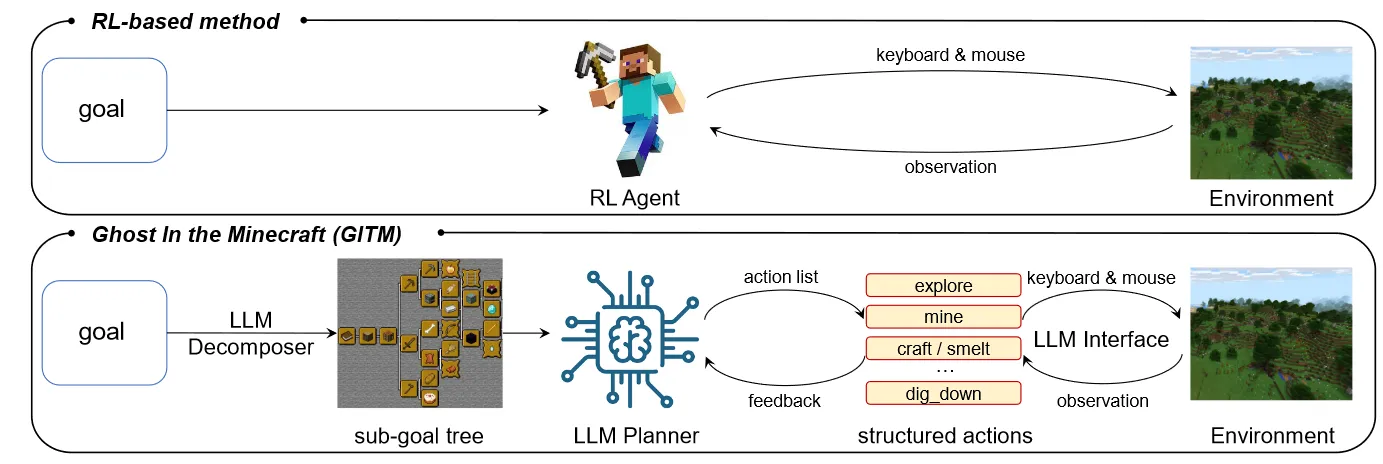
深度强化学习的流程可以抽象为以下步骤的重复:
本文主要探讨在收集经验过程中,环境自然结束(Terminated,包括目标成功,失败等)和人为截断(Truncated,主要为达到一定步数结束)对经验收集和训练产生的影响,以及如何对其进行处理。并对其进行了部分实验来比较性能。
现在是2023年5月17日凌晨00时57分,不知道是下午喝了那杯拿铁的缘故,还是因为这两天发生的事情,到现在依旧没有困意。此外,脑中也有很多想法在不断涌现和争辩。思来想去,与其在床上胡思乱想,亦或是借酒助眠,不如来工位写一篇文章,梳理一下脑中所想,将不断涌现的混乱的想法整理为有条理与逻辑的文本内容。
红豆生南国,春来发几枝?
愿君多采撷,此物最相思。
强化学习在算法实现时需要非常注意细节,否则网络很难收敛或没有训练效果。本文主要记录我在实现各种强化学习算法时踩到的一些坑以及需要注意的细节,持续更新......
以及附上我自己实现的RL算法库:https://github.com/KezhiAdore/RL-Algorithm

本文主要对于交叉熵的手动计算和PyTorch中的CrossEntropyLoss模块计算结果不一致的问题展开讨论,查阅了PyTorch的官方文档,最终发现是CrossEntropyLoss在计算交叉熵之前会对输入的概率分布进行一次SoftMax操作导致的。

最近在逐一复现RL算法过程中,策略梯度算法的收敛性一直有问题。经过一番探究和对比实验,学习了网上和书本上的很多实验代码之后,发现了代码实现中的一个小问题,即Policy Gradient在计算最终loss时求平均和求和对于网络训练的影响,本文将对此进行展开讨论。
先说结论:
在进行策略梯度下降优化策略时,可以对每个动作的loss逐一(for操作)进行反向传播后进行梯度下降,也可以对每个动作的loss求和(sum操作)之后进行反向传播后梯度下降,但尽量避免对所有动作的loss求平均(mean操作)之后进行反向传播后梯度下降,这会导致收敛速度较慢,甚至无法收敛。
具体的论证和实验过程见下文。
Zotero 是一款非常好用的开源文献管理软件,在对比了Endnote,Mendeley,Zotero之后最终我选择了Zotero作为我自己的文献管理软件,选择其的主要原因有:
本文主要介绍部分常用的Zotero插件,并附上其下载链接,同时谈谈使用感受。顺序按照我个人认为的好用程度排序。

本文围绕自由落体运动的估计,进行了线性滤波和非线性滤波的实验。下面这张图是源自西安交通大学蔡远利教授的《随即滤波与控制》课程。 该课程主要围绕估计,平滑与预测三方面讲解各类滤波方法。
手动标注数据集及视频分割程序下载见文章末。
