classAnimeDataItem(scrapy.Item): # define the fields for your item here like: name = scrapy.Field() #番剧名称 play=scrapy.Field() #总播放量 fllow=scrapy.Field() #追番人数 barrage=scrapy.Field() #弹幕数量 tags=scrapy.Field() #番剧标签,列表形式 pass
## 递归解析番剧信息表 defparse(self, response): data=json.loads(response.text) next_index=int(response.url[response.url.rfind("=")+1:])+1 if data['data']['size']==20: next_url=self.url_head+"&page="+str(next_index) yield scrapy.Request(next_url,callback=self.parse) for i in data['data']['list']: media_id=i['media_id'] detail_url=("https://www.bilibili.com/bangumi/media/md"+str(media_id)) yield scrapy.Request(detail_url,callback=self.parse_detail) pass
# 将逗号分割的字符串以逗号为分隔符转换成列表 defstr_to_list(str_data): for index,data inenumerate(str_data): tmp,start,end=[],0,0 while end!=len(data): if data[start:].find(',')==-1: end=len(data) tmp.append(data[start:end]) break end=start+data[start:].find(',') tmp.append(data[start:end]) start=end+1 str_data[index]=tmp
通过k-1项集构造k项集:
1 2 3 4 5 6 7 8 9 10 11 12
# Apriori算法连接步 单步实现 defmerge_list(l1,l2): length=len(l1) for i inrange(length-1): if l1[i]!=l2[i]: return'nope' if l1[-1]<l2[-1]: l=l1.copy() l.append(l2[-1]) return l else: return'nope'
判断列表的包含关系
1 2 3 4 5 6
# 判断l2是否包含在l1中 defis_exist(l1,l2): for i in l2: if i notin l1: returnFalse returnTrue
剪枝操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
# 利用min_sup和min_conf进行剪枝,即最小支持度和最小置信度,L_last为k-1项频繁集 defprune(L=[],L_last=0,min_sup=0,min_conf=0): tmp_L=[] if L_last==0or min_conf==0: for index,l inenumerate(L): if l[1]<min_sup: continue tmp_L.append(l) else: for index,l inenumerate(L): if l[1]<min_sup: continue for ll in L_last: if l[0][:-1]==ll[0]: if l[1]/ll[1]>=min_conf: tmp_L.append(l) return tmp_L
defApriori(data,min_sup,min_conf): # C:临时存储k项集 L:临时存储频繁k项集 L_save:保存频繁1-k项集 C,L,L_save=[],[],[] # 使用支持度计数来代替支持度进行计算 min_sup_count=min_sup*len(data) # 初始化一项集 for tags in data: for tag in tags: if C==[] or [tag] notin[x[0] for x in C]: C.append([[tag],0]) # 筛选出频繁一项集 L=C.copy() for index,l inenumerate(L): for tags in data: if is_exist(tags,l[0]): L[index][1]+=1 L=prune(L,min_sup=min_sup) L_save.append(L) whileTrue: # 由频繁k-1项集构造k项集 C=[] for l1 in L: for l2 in L: list_merge=merge_list(l1[0],l2[0]) if list_merge!='nope': C.append([list_merge,0]) # 统计频次,剪枝 L=C.copy() for index,l inenumerate(L): for tags in data: if is_exist(tags,l[0]): L[index][1]+=1 L=prune(L,L_save[-1],min_sup,min_conf) # L=空集时结束循环 if L==[]: return L_save L_save.append(L)
defdistance(point1,point2): dim=len(point1) if dim != len(point2): print('error! dim of point1 and point2 is not same') dist=0 for i inrange(dim): dist+=(point1[i]-point2[i])*(point1[i]-point2[i]) return math.sqrt(dist)
defget_category(dire,k,k_center): shape=np.array(dire).shape k_categories=[[] for col inrange(k)] for i inrange(shape[0]): Min=1 for j inrange(k): dist=distance(dire[i],k_center[j]) if dist<Min: Min=dist MinNum=j k_categories[MinNum].append(i) return k_categories
计算新的中心并重复
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# 最大迭代次数 Maxloop=500 k_center_new=k_center k_center=[] count=0 while(k_center!=k_center_new and count<Maxloop): count+=1 k_center=copy.deepcopy(k_center_new) k_categories=get_category(dire,k,k_center_new) for i inrange(shape[1]): for j inrange(k): temp=0 for w in k_categories[j]: temp+=dire[w][i] k_center_new[j][i]=temp/len(k_categories[j])
# 最大迭代次数 Maxloop=500 k_center_new=k_center k_center=[] count=0 while(k_center!=k_center_new and count<Maxloop): count+=1 k_center=copy.deepcopy(k_center_new) k_categories=get_category(dire,k,k_center_new) for i inrange(shape[1]): for j inrange(k): temp=0 for w in k_categories[j]: temp+=dire[w][i] k_center_new[j][i]=temp/len(k_categories[j]) return {'k_center':k_center,'k_categories':k_categories,'dire':dire,'k':k}
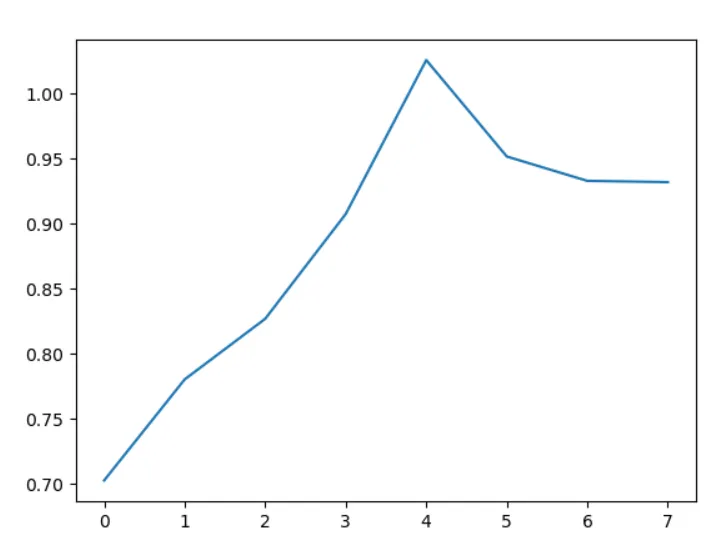
算法结果及评估
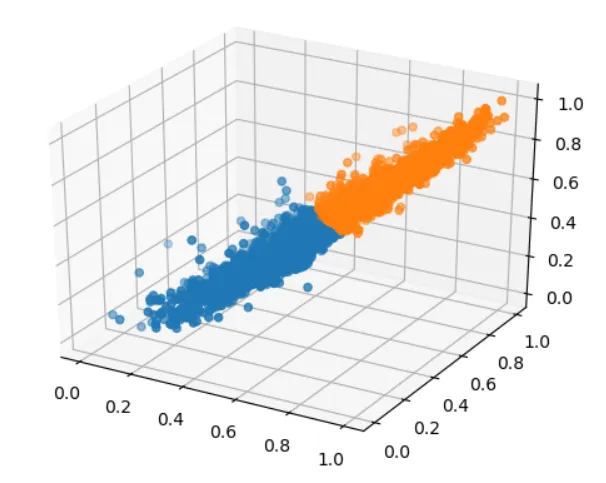
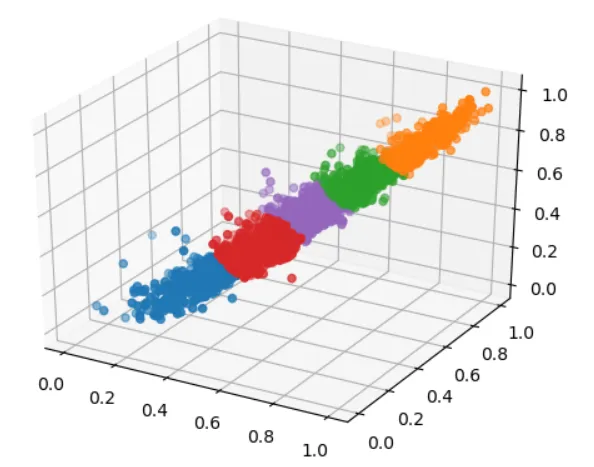
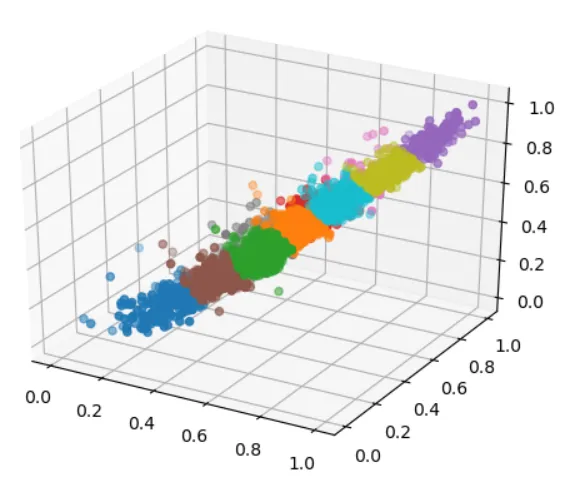
为了更直观的看到分类结果,将分类的点在三维空间中绘制出,用不同的颜色表示不同的类别。
绘图函数如下:
1 2 3 4 5 6 7 8 9 10 11 12
defshow_k_means(k_result): k,k_categories,dire=k_result['k'],k_result['k_categories'],k_result['dire'] for i inrange(k): x,y,z=[],[],[] for index in k_categories[i]: x.append(dire[index][0]) y.append(dire[index][1]) z.append(dire[index][2]) fig = plt.gcf() ax = fig.gca(projection='3d') ax.scatter(x,y,z) plt.show()
defdbi(k_result): k_center,k_categories,dire,k=k_result['k_center'],k_result['k_categories'],k_result['dire'],k_result['k'] # 簇内平均距离 k_ave_dist=[0for index inrange(k)] for i inrange(k): temp=0 for item in k_categories[i]: temp+=distance(k_center[i],dire[item]) k_ave_dist[i]=temp/len(k_categories[i]) # 簇中心之间距离 k_center_dist=[[0for row inrange(k)] for col inrange(k)] for i inrange(k): for j inrange(k): k_center_dist[i][j]=distance(k_center[i],k_center[j]) # 计算dbi DB=0 for i inrange(k): Max=0 for j inrange(k): if i !=j: temp=(k_ave_dist[i]+k_ave_dist[j])/k_center_dist[i][j] if temp>Max: Max=temp DB+=Max return DB/k