炼丹工业化——mlflow使用简介
丹药管理是炼丹术中很重要的部分。毕竟,当一批一批的丹药通过不同的材料和火候炼制出来之后,我们总是会产生如下需求:
- 对丹药效果进行评估,筛选出好的丹药
- 将一批丹药的效果进行对比,从而发现好的材料配比(超参数)
- 发现了一颗效果好的丹药,想要复现这颗丹药的生产过程
- ......
为了实现以上需求,我们便需要炼丹管理技术,简单来说,就是要在
代码,超参数,模型之间建立映射关系并对齐进行存储,以便支持后续的分析以及训练过程的回溯。由此,诞生了很多机器学习全生命周期管理软件,本文主要介绍一款开源软件:MLflow
的简单使用流程
安装
1 | pip install mlflow |
管理面板
启动管理面板:
1 | mlflow ui --host=127.0.0.1 --port 8000 |
管理面板的页面结构很简单,自行摸索即可。
这里主要说一下数据集中存储的方案。在多台机器跑同一个实验时,通常采用的方案是把所有的
log download
到一台机器上进行比较。这样手动管理十分繁杂且容易出错。mlflow
采用的是 client-server
结构,因此可以用一台机器作为服务器,其他机器在跑实验时通过访问
uri
将数据推送到服务器端,最后统一在服务器端进行查看比较即可。
一种实现思路是在一台服务器上部署 mlflow 并开放访问:
1 | mlflow ui --host=0.0.0.0 --port 8000 |
假设这台机器的 ip 为 192.168.1.12
那么对其他机器上的 uri 进行对应修改即可:
1 | mlflow.set_tracking_uri(uri="http://192.168.1.12:8000") |
此外也可以加入权限认证:
1 | mlflow server --app-name basic-auth |
关于权限认证更详细的内容见 MLflow Authentication — MLflow 2.11.2 documentation
MLflow 结构简介
MLflow 主要分为以下几个模块
MLflow Tracking:用来记录实验的
logging信息,包括parameters,metric等System Metrics:记录程序运行过程中的系统状态(CPU占用,内存占用,...)
MLflow Models:保存训练出来的模型
MLflow Model Registry:模型登记,用于对训练出的模型进行管理
MLflow Projects:项目管理模块,通过记录运行环境和程序入口,来实现
MLflow Plugins:支持第三方插件
MLflow 使用说明
MLflow 的使用可以支持机器学习项目的整个生命流程,如下图所示
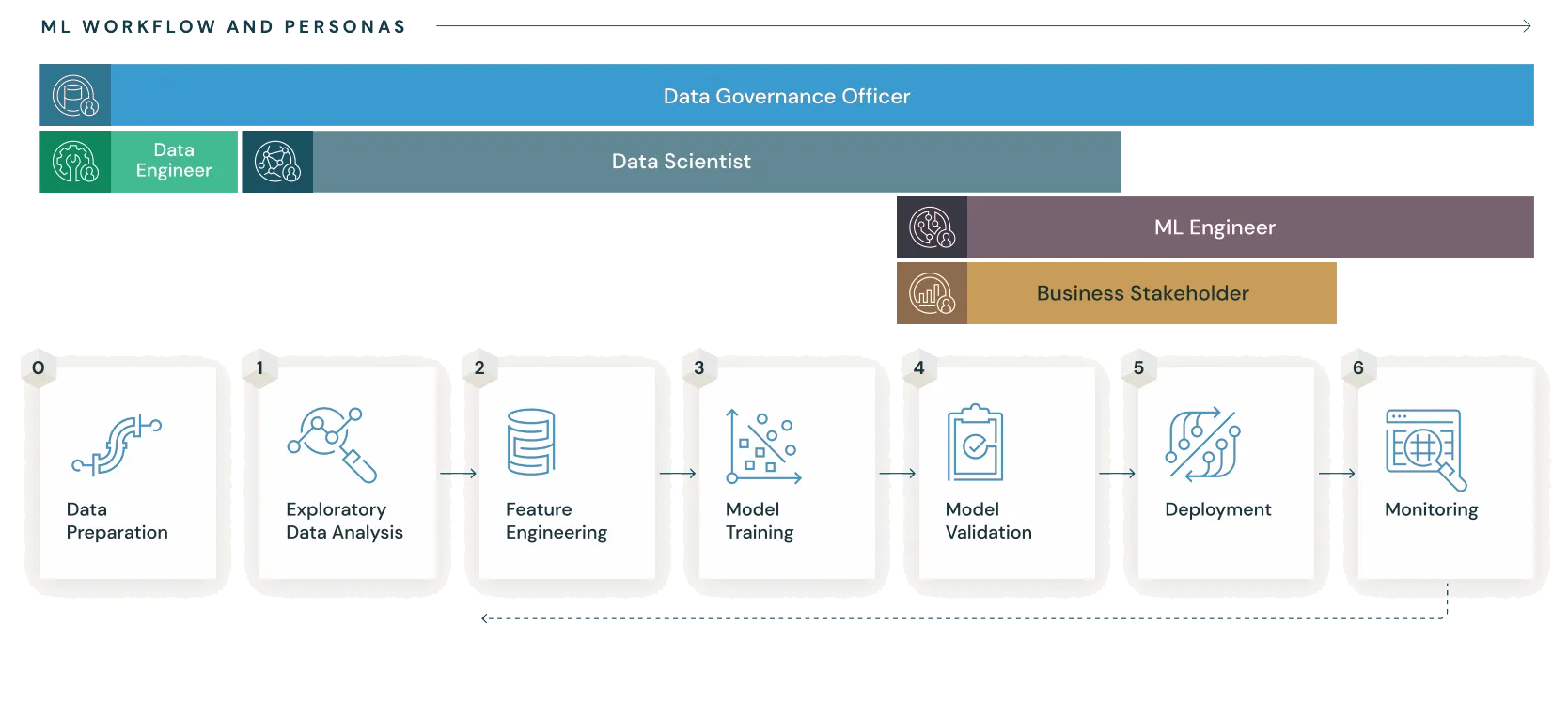 What is
MLflow? — MLflow 2.11.2 documentation
What is
MLflow? — MLflow 2.11.2 documentation
下面对 MLflow的各个部分使用逐一进行简单介绍
MLflow Tracking
Tracking 的主要作用类似于
tensorboard,即对训练的超参数和过程数据进行记录,使用如下:
1 | import mlflow |
其中:
mlflow.set_tracking_uri指定了mlflow数据存放的位置,不指定则默认为本地文件夹下存储mlflow.set_experiment定义实验名称,可以认为与project对应,同一个project的不同算法版本以及不同的超参数选取应使用同一个实验名称mlflow.log_param:记录某个超参数mlflow.log_parame:记录多个超参数,通过字典传入mlflow.log_metric:记录某个过程指标mlflow.log_metrics:记录多个过程指标,通过字典传入
此外,还有很多其他的函数来实现诸如:记录
image,记录matplotlib绘制的
figure,记录文件等,这里便不逐一列举了,可以参考官方文档:mlflow
— MLflow 2.11.2 documentation
Auto Logging
此外,MLflow
也支持对过程数据自动进行追踪,使用方法如下:
1 | import mlflow |
自动追踪记录会对哪些数据记录我还没有尝试过,这里放一张官方文档的示意图:
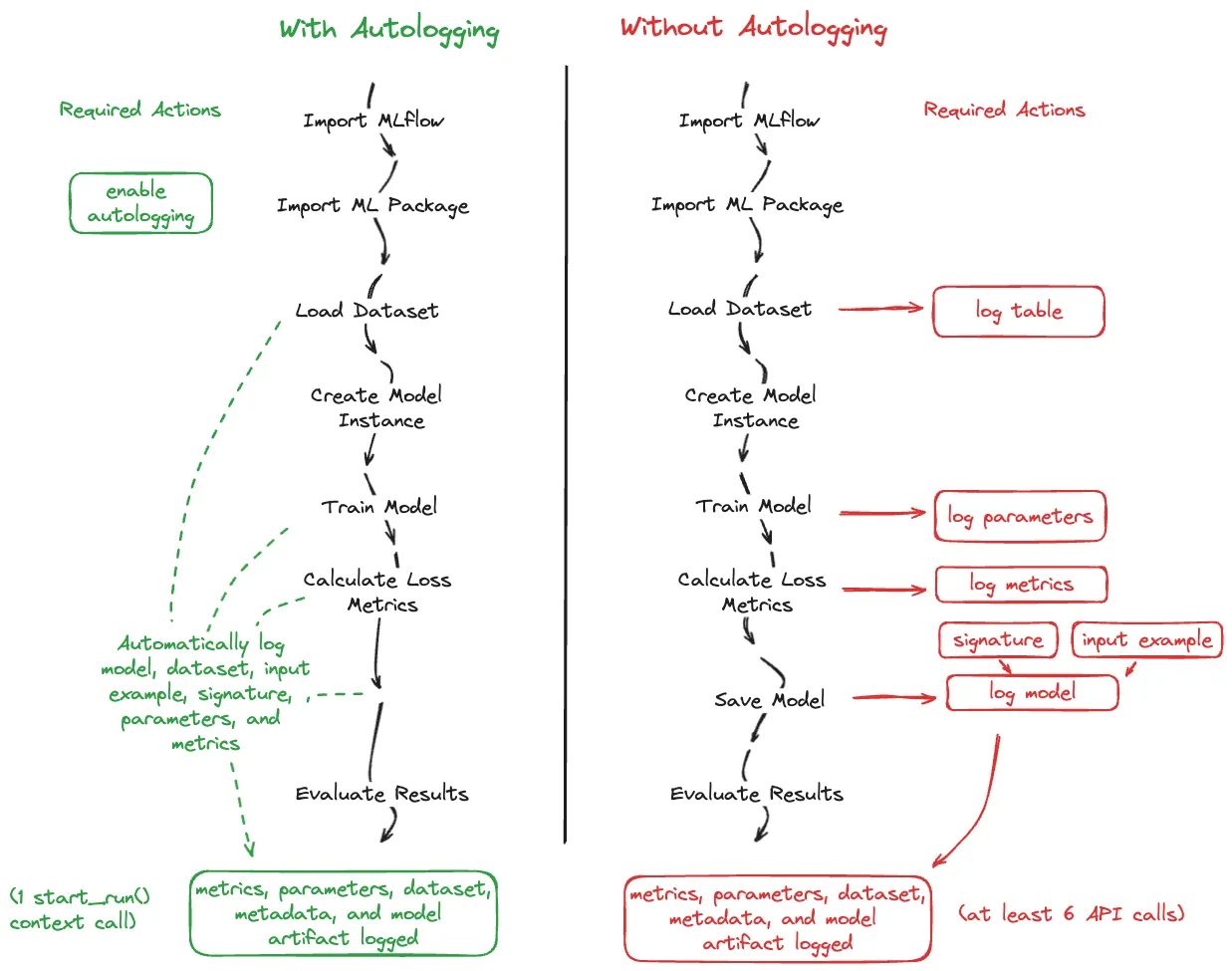
Getting Started with MLflow — MLflow 2.11.2 documentation
关于 Auto Logging 的进一步说明可以参考:Automatic Logging with MLflow Tracking — MLflow 2.11.2 documentation
System Metrics
System Metrics 模块用来监控在训练过程中的各项系统状态指标,使用方法如下:
1 | import mlflow |
系统监控在默认情况下是不打开的,如需记录则执行以上代码即可
MLflow Models
MLflow Models
模块主要用于存储代码训练产生的模型,对于不同的深度学习库该模块有不同的实现,以
pytorch 为例:
1 | import numpy as np |
更详细的内容见:MLflow Models — MLflow 2.11.2 documentation
MLflow Model Registry
Model Registry 的功能简单来说就是对生产出的模型进行版本管理,在 ui 面板上操作即可。具体流程见 MLflow Model Registry — MLflow 2.11.2 documentation
MLflow Projects
MLflow Projects 通过一个配置文件来记录代码运行环境以及程序入口,从而便于对程序进行分发。
其主要结构包含三部分内容:
- Name:项目名称
- Entry Points:程序入口,可以带参,并且可以使用多个入口组成 pipeline
- Environment:运行环境配置,支持
conda,Vitrualenv以及Docker
在项目的根目录新建
MLproject,并向其中写入配置,例如:
1 | name: My Project |
仿照上面的例子创建好配置文件后,便可以使用 mlflow
来自动运行:
1 | mlflow run /path/to/project --env-manager=conda |
此外,也可以指定 Github 仓库来运行项目:
1 | mlflow run git@github.com:mlflow/mlflow-example.git -P alpha=0.5 |
对于 mlflow run 的更多信息可以使用
mlflow run --help 来进行查看。
关于 MLflow Project 更详细的说明见 MLflow
Projects — MLflow 2.11.2 documentation
MLflow Plugins
MLflow 是一个开源项目,并且支持各种各样的插件,各位也可以开发相应的插件来满足自己的个性化需求。关于插件的开发,安装,以及当前社区流行的插件见 MLflow Plugins — MLflow 2.11.2 documentation